
Elon Musk describes what’s coming as a Supersonic Tsunami of converging exponentials. AI isn’t improving linearly anymore. We’re watching three exponential curves hit their inflection points simultaneously: compute scaling, model capabilities, and infrastructure deployment. When exponentials converge, you don’t get incremental progress. You get phase shifts.
Let me give you the raw numbers that demonstrate just how fast this is moving. What’s happening with AI revenue right now is unprecedented in the history of business. Anthropic hit $14 billion in annualized revenue in February 2026, growing from $1 billion just 14 months earlier. That figure has since surpassed $19 billion, more than doubling from $9 billion at the end of 2025. There is simply no precedent for this in B2B software.
And yet most people do not know who Anthropic is and what they do. Also, to understand what that means: Anthropic’s monthly revenue run rate is now roughly $1.6 billion per month, and it keeps accelerating. Anthropic projects as much as $70 billion in revenue by 2028.
OpenAI reached $25 billion in annualized revenue at the end of February 2026, up from $21.4 billion at year-end 2025, with full-year 2025 revenue coming in at $13.1 billion. Both companies are now valued in the hundreds of billions, Anthropic at $380 billion following its $30 billion Series G. OpenAI’s most recent private round in February 2026 valued it at approximately $730 billion, with an IPO potentially targeting a $1 trillion valuation.
Nvidia’s, Jensen Huang recently finalized a $30 billion investment in OpenAI and a $10 billion investment in Anthropic, and told investors these will likely be Nvidia’s last private investments in either company, because both are heading toward public markets. Think about that: the CEO of Nvidia, who has better visibility into AI infrastructure demand than anyone on Earth, made $40 billion in bets on these two companies as his final pre-IPO move.
What’s driving this revenue? It’s not IT budgets anymore. The models — Claude from Anthropic, GPT-5 from OpenAI — have crossed a threshold. They’re now competing with labour budgets.
Companies aren’t buying AI to replace servers. They’re buying AI to augment and ultimately displace human labour.
What’s the breakthrough use case? Coding. Claude Code (Anthropic’s agentic coding tool) now has run-rate revenue above $2.5 billion, having more than doubled since the beginning of 2026. Business subscriptions have quadrupled since the start of the year, and enterprise use has grown to represent over half of all Claude Code revenue.
Now you can buy intelligence on a metered basis. Pay per token. No recruiting, no vetting, no retention, no equity. Just intelligence as a utility. Consumers pay $20/month. Enterprise power users pay $200/month. And companies are spending millions per year because the ROI is there.
The Infrastructure Equation
Here’s the infrastructure reality that almost nobody is talking about loudly enough.
The five largest US hyperscalers — Microsoft, Alphabet, Amazon, Meta, and Oracle — have collectively committed to spending ~$690 billion on capital expenditure in 2026 alone, nearly doubling 2025 levels. The vast majority is directed at AI compute, data centers, and networking.
Total global AI spending is forecast to hit $2.5 trillion in 2026, a 44% increase over 2025, according to Gartner. Data centers, GPUs, power generation, chip fabrication. This is the largest infrastructure buildout in the history of technology, by a wide margin.
The rule of thumb in this industry: roughly $50 billion per gigawatt of infrastructure, and approximately $10 billion of annual revenue per gigawatt. Energy equals intelligence.
On a recent earnings call, Jensen Huang estimated that between $3 trillion and $4 trillion will be spent on AI infrastructure by the end of the decade. TechCrunch
This isn’t hype. This is capital deployment at a scale that rewrites the rules of what’s possible. When you’re spending $50 billion on a single data center and generating $10 billion a year in revenue from it, you’re not building a product… you’re building a new economic substrate. You’re building the electricity grid of the 21st century.
The tsunami is here. The question is whether you’re building on the wave or getting buried by it.
AI: The Capability Jump
Those revenue numbers I just showed you are driven by real capability breakthroughs happening right now.
Start here: neuromorphic chips just solved complex physics simulations at 1,000x better energy efficiency than supercomputers. That’s not 10% better. That’s three orders of magnitude. When compute gets that cheap, you don’t just do the same things faster. You do entirely new things that were economically impossible before.
Drug discovery moves from weeks on supercomputer clusters to hours on desktop chips. Climate modeling that required national labs runs on university hardware. Real-time protein folding for personalized cancer treatment becomes viable. This is Dematerialization, demonetization, and democratization followed by disruption (four of the Six D’s) in action.
Meanwhile, China’s DeepSeek launches V4 next-gen models through Huawei and Cambricon instead of U.S. chips. The AI race is officially multi-polar. OpenAI is preparing for the largest AI IPO in history.
And NVIDIA releases Alpamayo — the “ChatGPT moment for the physical world” — bringing reasoning to autonomous vehicles.
What it means: AI just moved from virtual to physical, from U.S.-dominated to globally distributed, and from expensive to radically cheap. All in the same week. And the revenue is proving it’s not experimental anymore: companies like Palantir, the U.S. military, and NVIDIA are running this in production for existential wartime operations.
Energy: Solving the Bottleneck
The elephant in the room: AI requires massive power. Those $50 billion data centers being built need gigawatts of electricity – and the grid was never designed for this.
Global electricity demand from data centers is set to more than double by 2030, reaching around 945 terawatt-hours: roughly equivalent to Japan’s entire annual electricity consumption. In the United States alone, data centers will account for nearly half of all electricity demand growth between now and 2030. AI will drive most of this increase, with electricity demand from AI-optimized data centers expected to more than quadruple by 2030.
Lawrence Berkeley National Laboratory projects U.S. data center electricity demand will grow from 176 TWh in 2023 to between 325 and 580 TWh by 2028 — representing up to 12% of total U.S. electricity consumption.
The grid was simply not built for this. Interconnection queues are backed up two to three years, transmission permitting takes a decade, and the power plants needed don’t yet exist. In just northern Virginia, a 2024 voltage fluctuation triggered the simultaneous disconnection of 60 data centers, a preview of what grid strain at scale actually looks like.
But look at what’s happening to solve it.
Nuclear Fusion is converging – fast: China’s “Artificial Sun” EAST reactor recently breached a major fusion plasma density barrier that researchers had long considered impossible to cross. In 2025, France’s WEST tokamak sustained plasma for over twenty minutes, while EAST maintained high-confinement plasma for nearly eighteen minutes — demonstrating the levels of stability required for commercial operation.
On the private side, the race has never moved faster. Commonwealth Fusion Systems has raised nearly $3 billion, including investments from Nvidia and Google, with the ultimate goal of a 400-megawatt power plant — enough to power around 280,000 average U.S. homes. CFS’s SPARC demonstration machine is expected to produce its first plasma in 2026 and achieve net fusion energy shortly after — the first commercially relevant design to produce more power than it consumes. That paves the way for ARC, their grid-connected power plant, targeted for the early 2030s.
Helion Energy has also begun construction of its first commercial fusion plant, designed to supply power directly to Microsoft’s data centers starting from 2028.
Private fusion investment has mushroomed, growing to $10.6 billion between 2021 and 2025, with the number of private fusion companies more than doubling from 23 to 53 in the same period.
The timeline is compressing. “Fusion in 30 years away” is becoming “Fusion this decade.” Fusion timelines are collapsing in real time — and AI is actually helping accelerate the plasma physics research itself. The irony: the technology that creates the power problem may also be helping solve it.
The wild card: Tesla Terafab: On March 14, 2026, Elon Musk announced on X that the “Terafab Project launches in 7 days” (March 21st).
So, what is Terafab? Musk first outlined the concept at Tesla’s 2025 shareholder meeting, describing a chip fabrication facility comparable in scale to TSMC’s largest plants. During Tesla’s January 2026 earnings call, he confirmed the company would “have to build a Tesla TeraFab: a very big fab that includes logic, memory and packaging, domestically” to avoid hitting a hard ceiling on chip supply in three to four years.
The facility is designed to produce between 100 and 200 billion custom AI and memory chips per year, with an initial target of 100,000 wafer starts per month and an ambition to scale toward one million, roughly 70% of TSMC’s total output, concentrated in a single U.S. facility. The project carries an estimated cost of approximately $25 billion. Tesla’s fifth-generation AI chip, AI5, is expected to be among the first products fabricated at Terafab, with small-batch production in 2026 and volume production projected for 2027.
To be precise: March 21st almost certainly marks the formal kickoff: a groundbreaking or announcement event, not a fully operational fab. Semiconductor fabs of this scale take years to build and commission. But the signal matters enormously. Tesla is joining Apple, Google, Amazon, and Microsoft in a new category of tech company: one that controls its own silicon. When the largest AI compute consumers own their own chip supply chains, the semiconductor industry is permanently restructured.
What It All Means: The energy bottleneck that threatened to constrain AI is being attacked from every direction simultaneously: fusion physics breakthroughs, private capital pouring into next-generation reactors, nuclear power plant revivals, and vertical integration of the chip supply chain. This is abundance thinking in action. When problems get big enough, fast enough, the solutions scale to match.
The constraint isn’t permanent. It never was.
The Supersonic Tsunami: How It All Connects
Here’s what Elon understood: these are not separate trends. They’re one interlocking system.
Neuromorphic chips make AI 1,000x more efficient → inference becomes cheap enough to deploy everywhere → agentic systems run locally in robots and cars. Fusion energy solves the power bottleneck → enables massive AI training clusters → next-gen frontier models get deployed in humanoids → robots work in any environment and can be launched to orbit on Starship for space manufacturing.
And the capital is already flowing. $1 trillion in infrastructure. $50 billion data centers generating $10 billion annually. Companies going from $1 billion to $14 billion in 14 months. This is not speculation…. it’s deployment at a scale that’s rewriting the rules.
The companies being built right now aren’t competing with 2024 business models.
Today’s companies are competing in an “Abundance Economy” where everything becomes possible, where intelligence is free, energy is abundant, labour is robotic, and orbital access is cheap.
As well, the professions are capitulating faster than the machines can replace them. An AMA survey found 81 percent of physicians now use AI, more than double the 2023 rate. New US Senate guidelines permit aides to use Gemini, ChatGPT, and Copilot for official work.
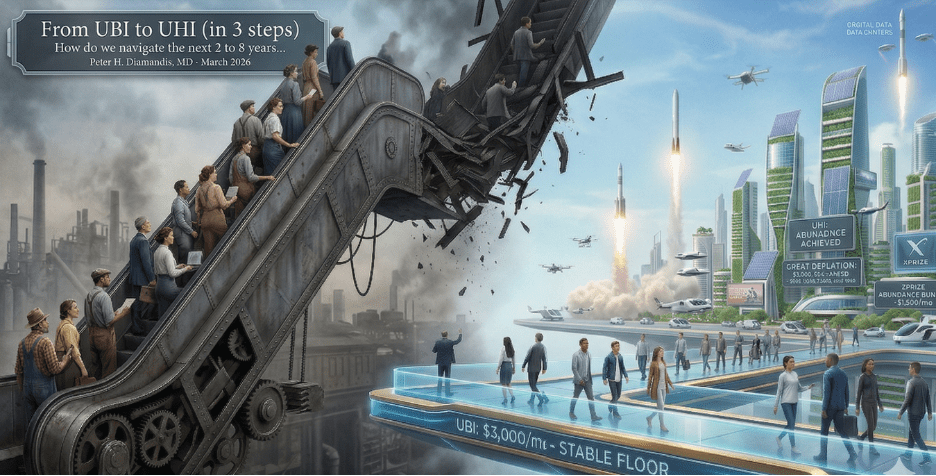
Large language models, multimodal reasoning systems, and humanoid robots are not displacing one type of work — they are displacing all types of work, and the economic value of human time itself, across every sector, simultaneously.
There is no adjacent labor category to retrain into. The escalator that carried workers from disrupted industries to new ones for two centuries has no destination… it is crumbling.
That future isn’t ten years away. It’s arriving now and deploying over the next 12-24 months.
This will cause chaos particularly for Gen Z. How do they prepare for work in the AI era? Biblical prophecy reveals that in this world that no longer believes that God is in control. and that a spiritual war is intensifying as Satan the prince of this world does his utmost to retain rulership of the world, people worldwide will embrace Satan’s Antichrist ruler that has supernatural powers and promises peace and prosperity. Watch as Biblical end times prophecies unfold in our time.
